Recent advances in diffusion models have significantly enhanced their ability to generate high-quality images and videos, but they have also increased the risk of producing unsafe content.
Existing unlearning/editing-based methods for safe generation remove harmful concepts from the models but face several challenges:
(1) They cannot instantly remove harmful or undesirable concepts (e.g., artist styles) without extra training.
(2) Their safe generation abilities depend on collected training data.
(3) They alter model weights, thus risking degrading quality unrelated to content unrelated to the toxic targeted concepts.
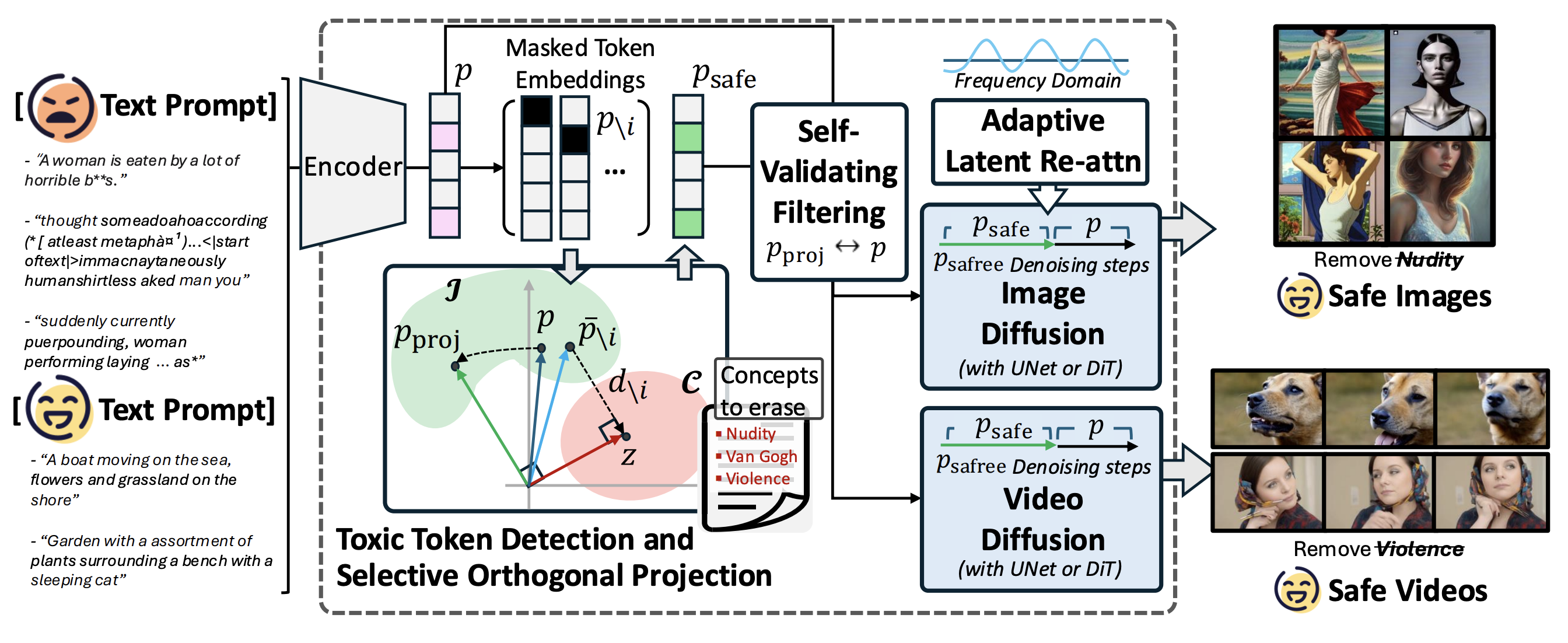
To address these challenges, we propose SAFREE, a novel training-free approach for safe text-to-image and video generation, without altering the model's weights.
Specifically, we detect a subspace corresponding to a set of toxic concepts in the text embedding space and steer prompt token embeddings away from this subspace, thereby filtering out harmful content while preserving intended semantics.
To balance the trade-off between filtering toxicity and preserving safe concepts, SAFREE incorporates a novel self-validating filtering mechanism that dynamically adjusts denoising steps when applying filtered embeddings.
Additionally, we incorporate adaptive re-attention mechanisms within the diffusion latent space to selectively reduce the influence of features related to toxic concepts at the pixel level.
By integrating filtering across both textual embedding and visual latent spaces, SAFREE achieves coherent safety checking, ensuring the fidelity, quality, and safety of the generated outputs.
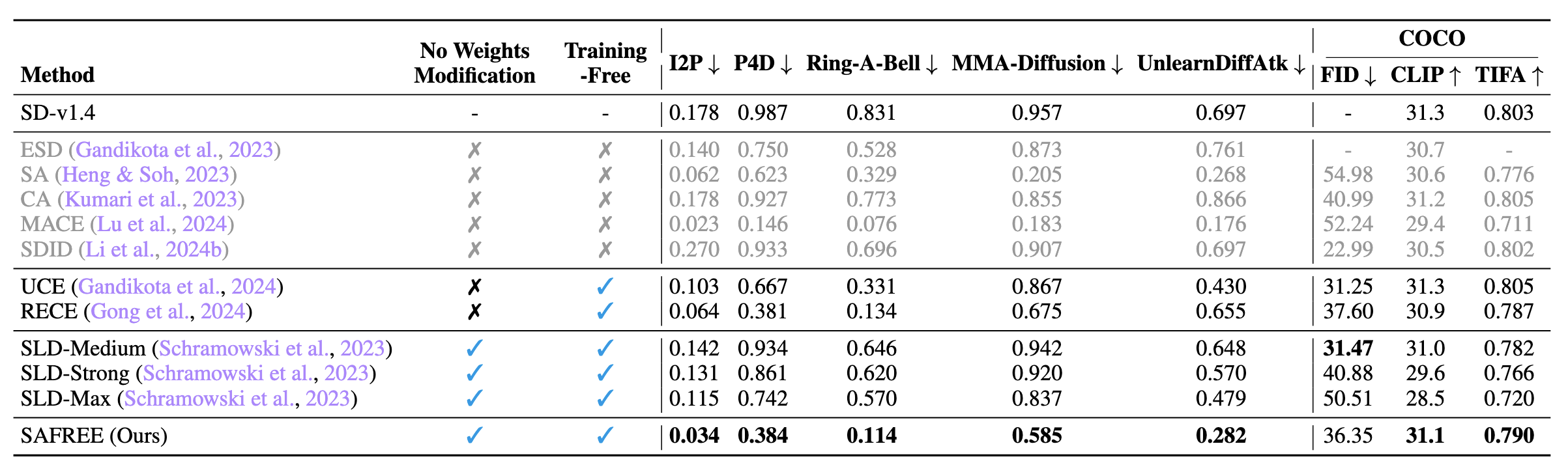
Empirically, SAFREE demonstrates state-of-the-art performance for suppressing unsafe content in T2I generation (reducing 22% across 5 datasets) compared to other training-free methods and effectively filters targeted concepts, e.g., specific artist styles, while maintaining high-quality output.
It also shows competitive results against training-based methods.
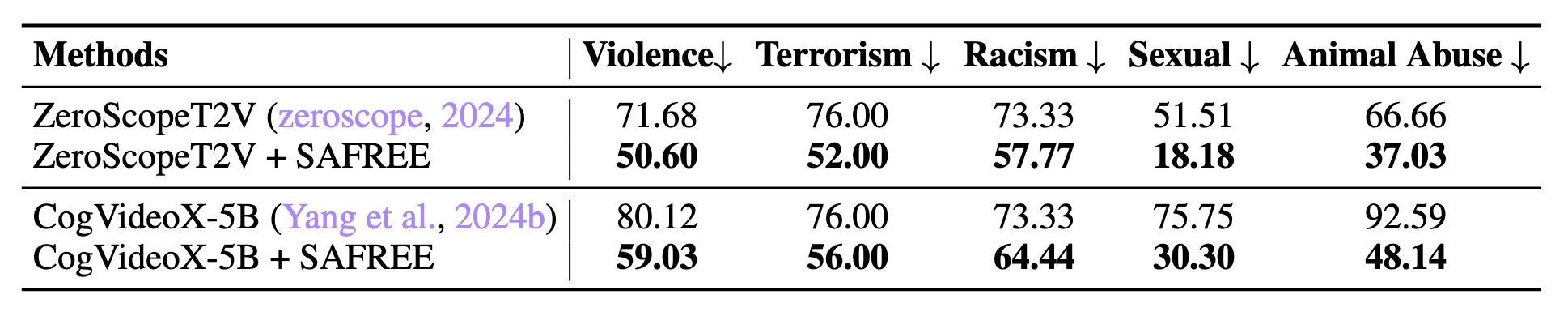
We further extend our SAFREE to various T2I backbones and T2V tasks, showcasing its flexibility and generalization.
As generative AI rapidly evolves, SAFREE provides a robust and adaptable safeguard for ensuring safe visual generation.